Estos días me he propuesto hacer limpieza de backups y aplicar correctamente la regla 3-2-1 de las copias de seguridad porque hasta ahora no tenía un backup completo en una segunda ubicación. Además, he borrado más de 2,5 Tb de datos duplicados y triplicados que seguía almacenando por puro Diógenes digital.
Hasta hace poco más de un año, mi plan de backup de los dos servidores era un poco heterodoxo. Básicamente tenía unos script que copiaban todo lo importante, nube privada, contenedores docker, bases de datos, lo comprimían y lo enviaban al servidor de backup, llar. La cosa es que sobreescribían la copia de la noche anterior lo que es una chapuza y bastante peligroso si los problemas te pillan fuera de casa y no puedes proteger la copia. ¿Tenía backup? Sí. ¿Me fiaba de él? Lo justo. Y así no se puede vivir.

Por si no fuera suficiente, las copias no salían de llar con lo que no tenía respaldo en otra localización. Intenté en un par de ocasiones configurar una raspi con un disco en casa de mis padres pero la salida a internet era complicada (¡mil gracias, Telecable!).
El plan#
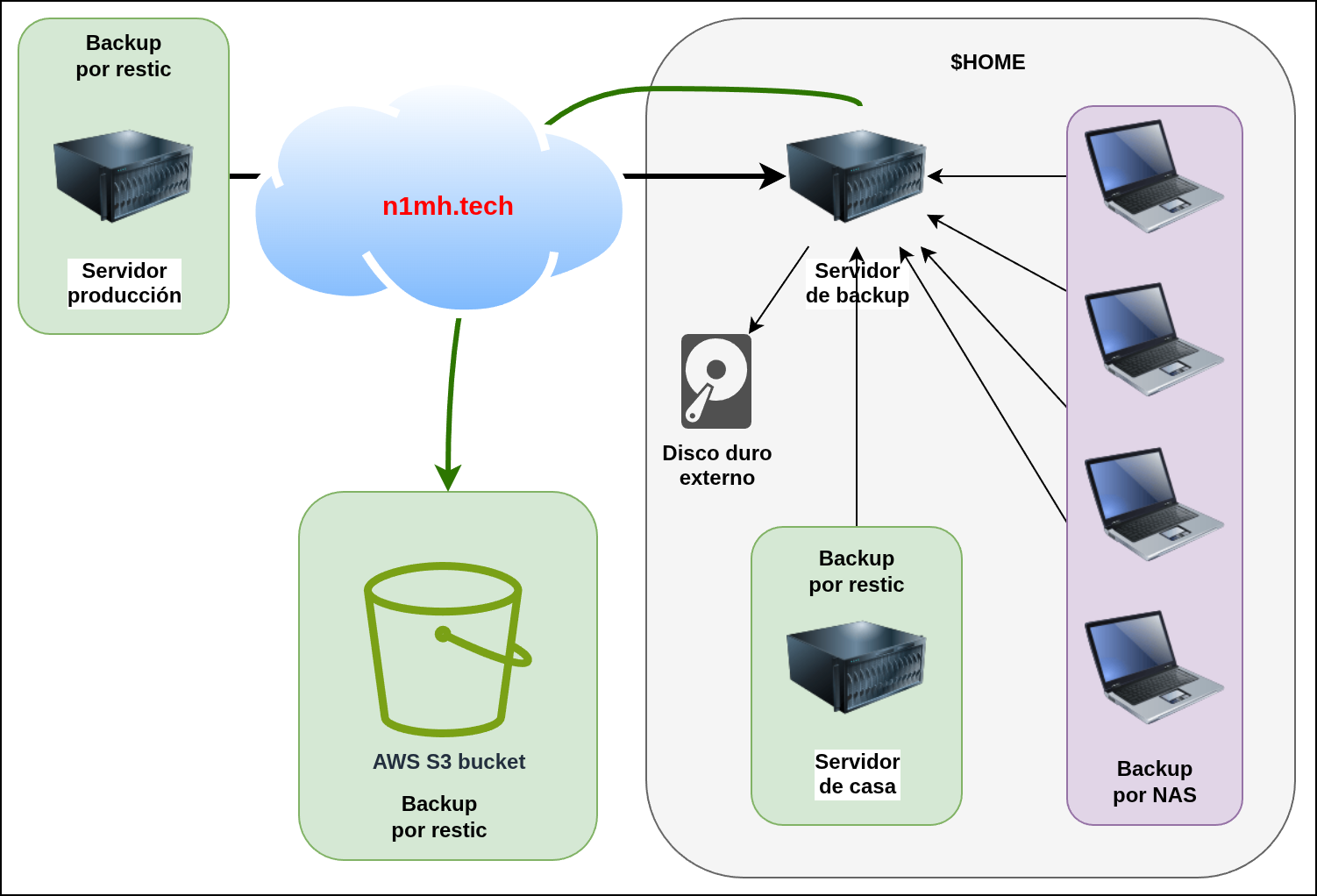
Necesitaba un nuevo plan de backup y, en esta ocasión, todo el backup giró alrededor de sacar los datos de casa y meterlos en un bucket en AWS S3. Para ello, mantendría ciertas cosas que funcionaban bien y cambiaría las que no iban tan bien. En resumen:
llarseguirá siendo el servidor de backup y se podrá acceder al disco mediantesambaossh- los ordenadores de casa harán backup con
deja-dupsobresamba - los servidores (externos o de casa) harán backup con
resticsobressh - las 3 copias de los datos serán el ordenador de origen, la copia en
llary una copia mensual que hago de todo a un disco duro externo - los 2 almacenamientos diferentes serán
llary el disco duro - la localización diferente será un bucket en AWS S3
La foto final#
restic#
En el caso del resto de servidores, he dejado de usar mis scripts en bash de hace veinte años y me he pasado a restic. Su funcionamiento es sencillo, configuras un repositorio donde guardar el backup (puede ser un disco, un volumen de red, un directorio al final de un SSH o un bucket S3) y le das la periodicidad que quieras y ya está. El primer backup es completo y el resto, incrementales y te pide una frase de paso para cifrarlos in transit. Es una joya que lamento no haber usado antes, me habría ahorrado muchos líos.
El servidor de backup#
Aunque la imagen de llar sea la de uno de esos monstruos enracables de varias U’s, es una raspberry pi de cuarta generación, 8Gb de RAM y arquitectura ARM que tiene enchufado un disco externo USB de 5Tb. El haber liberado la mitad del disco lo ha rejuvenecido un montón 😁. A este servidor se conectan los clientes de backup a través de NAS (un volumen de red compartido) y a través de SSH y openmediavault ayuda a gestionar todo, servicios y usuarios fácilmente.
Los ordenadores personales#
Los ordenadores que usamos en casa, todos linux, se conectan al volumen compartido a través del viejo y fiable Samba, usando deja-dup la copia linuxera de Time Machine de Apple. Es sencillo de configurar, se lanza el solito y cifra y mantiene los backups incrementales de forma transparente y sin darte cuenta.
El servidor casero#
El servidor que tengo en casa tiene unas pocas aplicaciones y un montón de teras. Entre las aplicaciones está nuestra nube privada, el servidor de minecraft o ciertas aplicaciones de servarr pero, el backup es bastante sencillo. Obviamente no tiene sentido hacer copia de seguridad de los 12Tb de material audiovisual pero sí de la nube privada que sólo son unos 300Gb (de momento). Así que, entre la nube privada y las configuraciones de los 17 contenedores que aloja, un backup completo se hace en poco más de 45 minutos, tirando de red local.
El servidor remoto#
El servidor remoto alberga toda la producción, esto es, un montón de WordPress que todavía están activos, la web de la asociación de montaña de mi padre e incluso esta misma web. Funciona con docker, las configuraciones, imágenes alojadas en AWS ECR y el código está en GitHub con lo que el backup es sólo de los volúmenes de los contenedores. Con restic y volcándolo en el servidor de backup a través de SSH no lleva más de 15 minutos hacer un backup completo.
El tercer backup#
Doy por supuesto que hay acceso a una cuenta en AWS y que se ha instalado y configurado AWS CLI, que es con lo que vamos a crear el bucket. Como alberga las copias de seguridad, vamos a cifrarlo y a bloquear cualquier intento de acceso para que los ficheros estén seguros.
Después sólo hay que ejecutar los siguientes comandos:
# Variables
export BUCKET="bucket_4_backups"
export REGION="eu-west-1"
# 1 Crear bucket
aws s3api create-bucket \
--bucket "$BUCKET" \
--region "$REGION" \
--create-bucket-configuration LocationConstraint="$REGION"
# 2 Bloquear TODO acceso público
aws s3api put-public-access-block \
--bucket "$BUCKET" \
--public-access-block-configuration \
BlockPublicAcls=true,IgnorePublicAcls=true,BlockPublicPolicy=true,RestrictPublicBuckets=true
# 3 Cifrado por defecto, SSE-S3-AES256
aws s3api put-bucket-encryption \
--bucket "$BUCKET" \
--server-side-encryption-configuration '{
"Rules": [
{
"ApplyServerSideEncryptionByDefault": { "SSEAlgorithm": "AES256" },
"BucketKeyEnabled": true
}
]
}'
# 4 Versioning
aws s3api put-bucket-versioning \
--bucket "$BUCKET" \
--versioning-configuration Status=Enabled
# 5 Política para denegar tráfico sin TLS
aws s3api put-bucket-policy \
--bucket "$BUCKET" \
--policy "{
\"Version\":\"2012-10-17\",
\"Statement\":[
{
\"Sid\":\"DenyInsecureTransport\",
\"Effect\":\"Deny\",
\"Principal\":\"*\",
\"Action\":\"s3:*\",\n \"Resource\":[
\"arn:aws:s3:::$BUCKET\",
\"arn:aws:s3:::$BUCKET/*\"
],
\"Condition\":{\"Bool\":{\"aws:SecureTransport\":\"false\"}}
}
]
}"
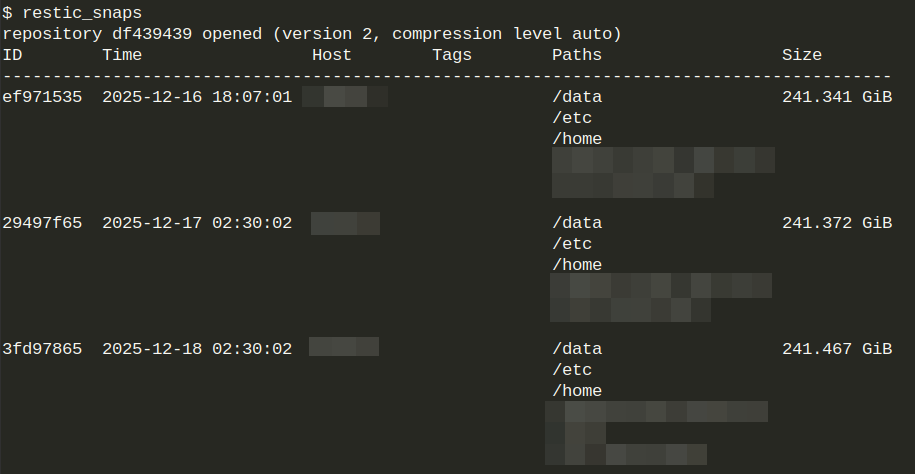
No hay configurado un lifecycle para que S3 borre los ficheros porque restic se encarga de eso (y más) de forma transparente. Un ejemplo, para terminar la turra:
Por último, un recordatorio: ¡hay que hacer backups! 😄